四川省計算機研究院科(kē)研團隊2篇論文成果,近期在數據庫領域國(guó)際頂會SIGMOD(Special Interest Group on Management Of Data)發表,題爲“A Hierarchical Contraction Scheme for Querying Big Graphs”“Parallel Rule Discovery from Large Datasets by Sampling”。相(xiàng)關研究成果對于實現高效大(dà)規模圖計(jì)算以及大(dà)規模數據集的規則發現,分(fēn)别提供了創新有效的解決思路(lù)。
A Hierarchical Contraction Scheme for Querying Big Graphs
需要耗費高昂成本及大(dà)量資源是大(dà)規模圖計(jì)算面臨的重大(dà)挑戰之一。如(rú)果能在資源有限的條件(jiàn)下實現大(dà)規模圖數據查詢,将有力促進大(dà)規模圖計(jì)算技術(shù)的應用,幫助企業降本增效,并滿足移動設備、安全計(jì)算等資源有限條件(jiàn)下的計(jì)算需求。
爲此,我院科(kē)研團隊提出了一種用單機(jī)查詢大(dà)規模圖數據的分(fēn)層壓縮方法。該方法創新性地将常規結構叠代壓縮爲超節點,并建立了一個可(kě)壓縮圖數據的層次結構,直到某一層級的壓縮圖能夠被完全放(fàng)進内存。對于每個使用中的查詢類Q,超節點攜帶了概要SQ,Q的查詢在可(kě)行情況下通過使用SQ來(lái)回答,否則就(jiù)鑽取到層次結構的下一層級并将圖數據解壓至有限大(dà)小。
爲了适應層次結構,我院科(kē)研團隊将現有的各種順序(單機(jī))算法中的邏輯和數據結構重複再利用。爲了維護層次結構,還(hái)提出了一種有界的增量算法,使其成本隻由輸入和輸出的變化大(dà)小決定。
通過使用真實數據和合成數據實驗驗證,在單機(jī)内存小于圖數據的7.6%時,層次計(jì)算結構不僅能精确得(de)出查詢答案,還(hái)能将各種應用程序的速度平均提升9.8倍,甚至比使用6台機(jī)器的并行圖系統快(kuài)120.1倍。
閱讀(dú)原文:
https://dl.acm.org/doi/10.1145/3514221.3517862

Parallel Rule Discovery from Large Datasets by Sampling
規則發現被研究者視爲幾十年(nián)以來(lái)的長期挑戰。從(cóng)大(dà)規模數據集中發現規則往往成本高昂,當規則被定義在多表中時,成本問(wèn)題更加驚人(rén)。
爲此,我院科(kē)研團隊創新性地提出了一種多輪抽樣策略來(lái)發現實體(tǐ)增強規則(REEs)。該規則支持常數模式和機(jī)器學習謂詞,可(kě)用于跨表實體(tǐ)解析和沖突解析。假設給定精度上界𝛼和召回率上界𝛽,該多輪抽樣策略可(kě)提供如(rú)下保證:精度保證,即從(cóng)樣本中發現的有效規則至少占比𝛼%;召回率保證,即全數據集上𝛽%的有效規則可(kě)以從(cóng)樣本中挖掘出來(lái)。
我院科(kē)研團隊還(hái)量化了樣本上規則的支持度、置信度與整個數據集上的對應關系。爲了與跨表規則中元組變量的數量相(xiàng)适應,采用深度學習Q-learning來(lái)選擇語義相(xiàng)關的謂詞。爲了提高召回率,還(hái)開發了一種基于模闆的方法來(lái)還(hái)原數據集中的常數模式。通過對該算法進行并行化處理(lǐ),從(cóng)而保證在使用更多處理(lǐ)器時減少運行時間。
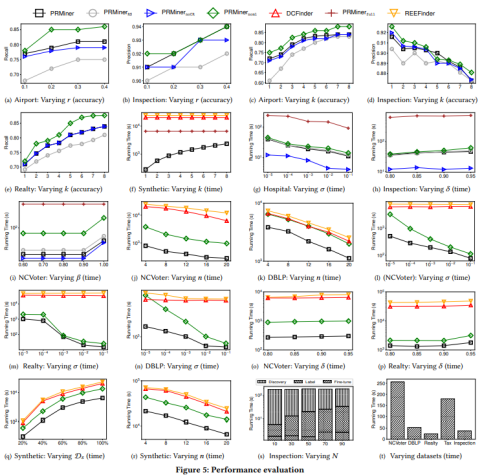
基于真實數據和合成數據實驗驗證,該方法在樣本率僅爲10%的情況下,可(kě)将REE發現速度提高12.2倍,召回率達到82%。
閱讀(dú)原文:
https://dl.acm.org/doi/10.1145/3514221.3526165
數讀(dú)SICS科(kē)研:
截至2022年(nián)9月下旬,研究院共發表/錄用高水平論文74篇,其中CCF A類61篇。申請(qǐng)知識産權共48項;其中申請(qǐng)專利/PCT共43項、授權發明專利5項;申請(qǐng)并授權軟件(jiàn)著作(zuò)權5項。