當地時間8月16至20日(rì),數據庫國(guó)際頂會——第47屆VLDB 2021(Very Large Date Bases)在丹麥哥本哈根召開。四川省計算機研究院(以下簡稱“深算院”)科(kē)研團隊及其合作(zuò)者的4篇論文在大(dà)會上發表。這4篇論文分(fēn)别在解決實體(tǐ)解析和沖突解析、單一來(lái)源SimRank查詢以及大(dà)規模圖計(jì)算等多個大(dà)數據重難點問(wèn)題上,取得(de)了領先性和突破性的創新成果。
一、論文标題:
《Parallel Discrepancy Detection and Incremental Detection》

*Parallel incremental algorithm PIncDet
實體(tǐ)解析(entity resolution)和沖突解析(conflict resolution) 一直是全球數據質量研究的長期挑戰,其中, ER是判斷哪些數據是同一個實體(tǐ), CR是解決同一實體(tǐ)中存在的語義沖突,語義沖突和不匹配的實體(tǐ)往往共存并且内在地互相(xiàng)幹擾。如(rú)何在同一個數據查錯和增量查錯過程中捕捉沖突并識别實體(tǐ)?深算院科(kē)研團隊及其合作(zuò)者在論文中,開創性地提出一種統一邏輯規則和機(jī)器學習模型的方法,通過該方法能夠發現數據中的冗餘、錯誤匹配和沖突,爲解決ER和CR問(wèn)題開辟了新思路(lù)。經真實數據集和基準測試,該方法在準确率上分(fēn)别比基于邏輯規則和機(jī)器學習模型的方法高33%和36%,同時比ER和CR單獨的檢測算法分(fēn)别高31%和41%,經實驗證明具有廣闊的理(lǐ)論和應用前景,未來(lái)可(kě)廣泛應用于電商、電信、金融反欺詐等多個領域。
論文鏈接:
static/file/p1351-tian.pdf
二、論文标題:
《DISK: A Distributed Framework for Single-Source SimRank with Accuracy Guarantee》
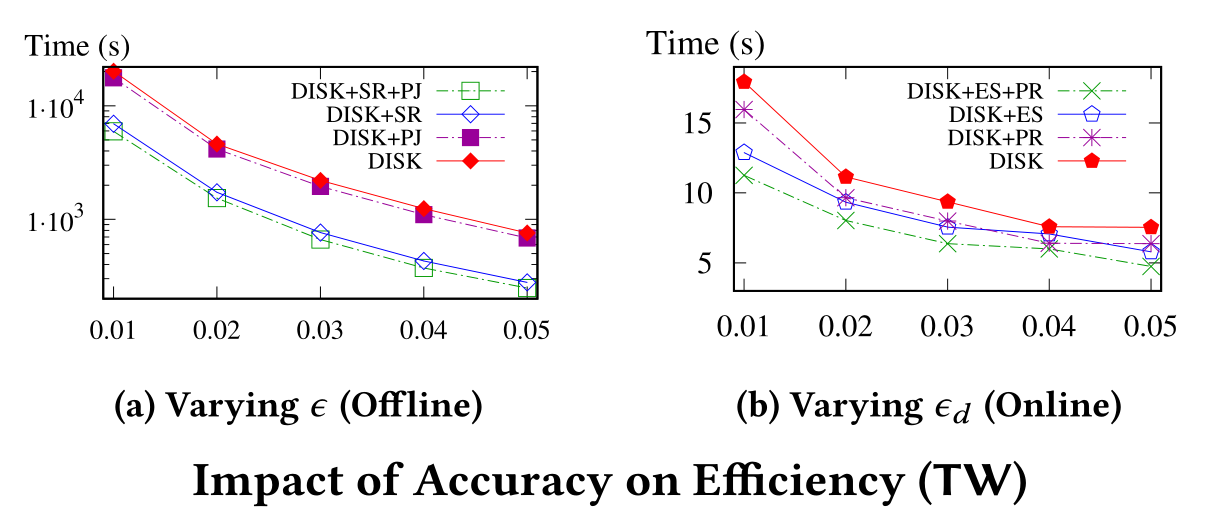
目前,處理(lǐ)和分(fēn)析大(dà)規模的圖數據已成新信息時代的必然趨勢,其中數據對象間的相(xiàng)似性度量在數據分(fēn)析和挖掘中起着關鍵作(zuò)用。業界提出的幾種基于鏈路(lù)的相(xiàng)似性度量方法中,單一來(lái)源的SimRank前途廣闊,被廣泛應用于社交媒體(tǐ)的朋友推薦、推文、群組等應用中。但(dàn)由于内存和并發性的限制,高效處理(lǐ)大(dà)型圖問(wèn)題已超出了單機(jī)能力,現實中不論是從(cóng)理(lǐ)論還(hái)是實驗結果來(lái)看(kàn),在分(fēn)布式環境中有效處理(lǐ)單一來(lái)源SimRank查詢不僅重要而且充滿挑戰。對此,深算院科(kē)研團隊及其合作(zuò)者開創性地提出了一個分(fēn)布式框架DISK,用于處理(lǐ)單一來(lái)源SimRank查詢。在該框架下,還(hái)提出了不同的優化技術(shù)來(lái)提高索引和查詢的效率。實驗證明,DISK可(kě)以擴展到數十億個點和邊的圖規模,并能在幾秒内回答确保精确度的在線查詢。
論文鏈接:
https://dl.acm.org/doi/10.5555/3430915.3442434
三、論文标題:
《GraphScope: A Unified Engine For Big Graph Processing》
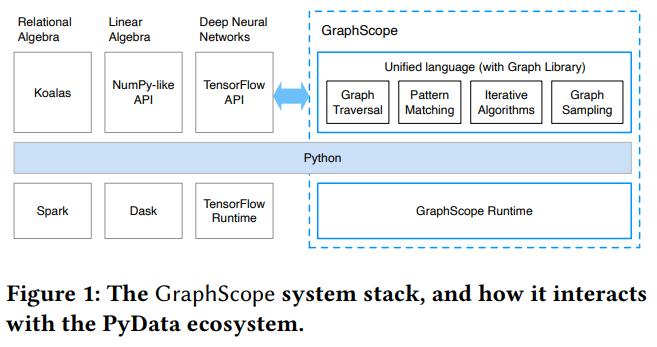
目前,在現代數據密集型應用程序的開發中,具有高級語言支持能力的分(fēn)布式執行引擎,如(rú)Koalas、Dask和TensorFlow已被廣泛采用并取得(de)巨大(dà)成功。但(dàn)若想要對異構數據進行更深入的分(fēn)析,從(cóng)而進一步解決更重要的問(wèn)題,往往需要使用涉及圖計(jì)算的分(fēn)析工(gōng)具進行替代,比如(rú)在産品和廣告推薦中經常用到的算法,都(dōu)屬于對圖數據的深度學習。然而現實中的圖應用往往更爲複雜,單個工(gōng)作(zuò)負載中經常交織着多種類型的圖計(jì)算系統,這些系統可(kě)能具有各不相(xiàng)同的編程模型和運行時間,從(cóng)而産生(shēng)多個系統中的數據表示、資源調度和性能調整等多類問(wèn)題。
針對以上難點,深算院科(kē)研團隊及其合作(zuò)者提出了一個能與其他(tā)數據處理(lǐ)系統無縫對接、通用的大(dà)規模圖計(jì)算處理(lǐ)引擎—GraphScope,該引擎提供了一個強大(dà)而簡潔的聲明式編程接口,并支持在通用數據并行計(jì)算系統中無縫整合高度優化的圖引擎。實驗證明,GraphScope的性能優于許多最先進的圖系統。
論文鏈接:
static/file/p2879-qian.pdf
四、論文标題:
《GraphScope: A Unified Engine For Big Graph Processing 》
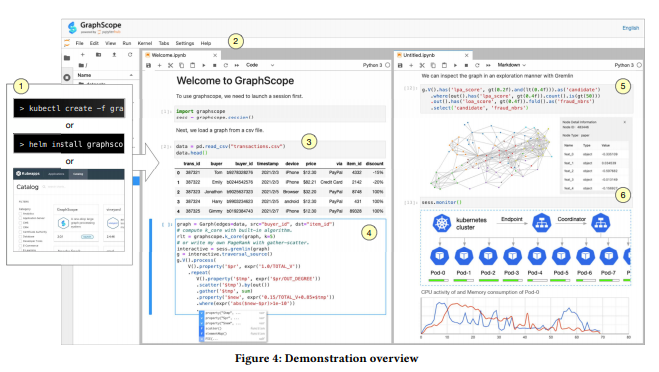
目前,圖計(jì)算被廣泛應用在互聯網、金融等互聯網領域。比如(rú)在電子商務平台上,一些賣家可(kě)能會協同買家進行欺詐性交易和評論,針對這類行爲,通過整合各種圖算法,能夠更好地捕捉欺詐行爲的協作(zuò)性質,從(cóng)而進行欺詐檢測。然而在現實中,随着不同圖處理(lǐ)系統的整合,出現了以下問(wèn)題:現有的圖處理(lǐ)系統通常是爲特定類型的計(jì)算設計(jì)的,其抽象編程模型和運行時可(kě)能非常不同,這給編程帶來(lái)了很大(dà)挑戰;許多系統(例如(rú)Apache Giraph)需要對底層的抽象編程模型有深入理(lǐ)解,這使得(de)隻有圖計(jì)算專家才能進行圖計(jì)算;與其他(tā)系統(如(rú)Spark)的互操作(zuò)通常涉及過多的數據轉換和移動,這可(kě)能會大(dà)大(dà)弱化整個執行性能。
針對上述難點,深算院科(kē)研團隊及其合作(zuò)者開創性地提出了一站(zhàn)式大(dà)規模圖數據處理(lǐ)系統GraphScope,旨在爲不同種類的圖計(jì)算任務提供一個一站(zhàn)式的高效解決方案,大(dà)大(dà)降低了圖計(jì)算門(mén)檻。同時,GraphScope的性能遙遙領先于同類系統,經實測GraphScope在萬億規模的海量圖數據上實現了2.86倍的速度提升,并被證明在風(fēng)控、金融反欺詐等多個關鍵互聯網領域,能實現重要的業務新價值。
論文鏈接:
static/file/p2703-xu.pdf